阿尔脉联合上海药物所发布生物医药文献的化学信息自动提取系统
发布于 2023-09-27 由 zhaojunli 发布

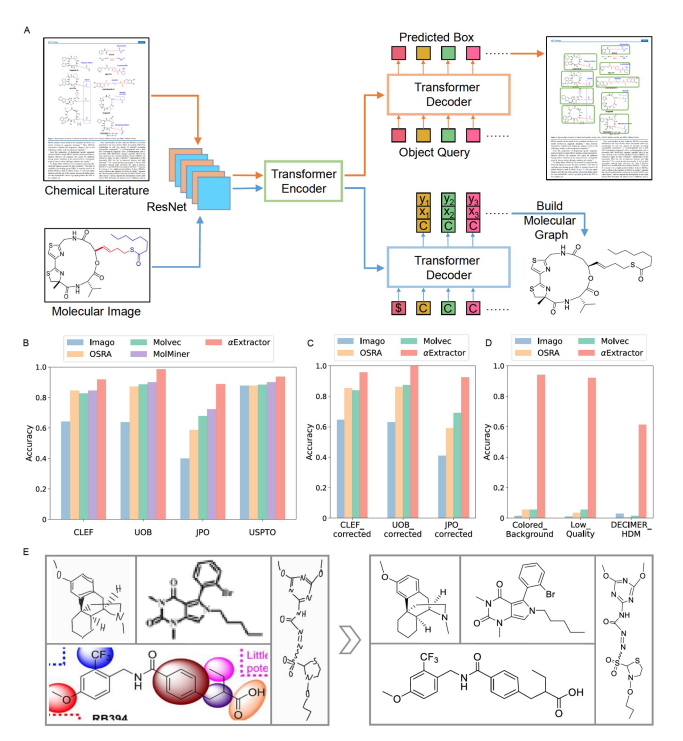
图1. αExtractor系统的架构和性能
在这项工作中,阿尔脉联合上海药物所结合图像注释、目标检测和合成计算机视觉等技术,开发了一个从文献中自动提取化学结构的深度学习系统。凭借着高的识别精度和处理速度,αExtractor有望助力于生物医药文献的自动化挖掘和数据驱动的分子设计。为了方便社区,αExtractor现在可以在线上免费使用(https://extractor.alphama.com.cn/csr),同时阿尔脉还提供了功能更加丰富、体验更加完善的商业版(https://patmap.alphama.com.cn)。
推荐文章
关注阿尔脉公众号

-获取更多-
精彩内容
随时掌握最新动态
关注阿尔脉领英

-获取更多-
精彩内容
随时掌握最新动态